|
I am a passionate Researcher and completed my graduation with University Silver Medal for securing the first rank in B.Tech(Hons.) Computer Science and Engineering (Artificial Intelligence and Machine Learning) from UPES, India.
I have worked as an ML Engineer at Energy Market Analytics, as an MLOps Engineer at Railofy, and as a Data Scientist at Cognizant. Helping build CORD.ai, a Community that enables Collaborative Open Research in Deep Learning. Also, passed professional certifications to validate my knowledge on Azure Fullstack, GCP ML, AWS ML, & Databricks ML. |

|
|
|
 |
Mayank Mishra, Nikunj Bansal, Tanmay Sarkar, & Tanupriya Choudhury Introducing Allergen30, a custom-made dataset with 6,000+ images of 30 commonly used food items that can trigger an allergic reaction within the human body. |
 |
Tanmay Sarkar, Tanupriya Choudhury, Nikunj Bansal, & Arunachalaeshwaran V R Introducing, the Dataset for Adulterated Red Chilli Powder with Brick Powder. It contains high-quality images of Red Chilli Powder adulteration with Red Brick Powder at 12 different proportions:- 0%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, and 100% adulterant. |
 |
Ritu Agarwal, Nikunj Bansal, Tanupriya Choudhury, Tanmay Sarkar, & Neelu Jyothi Ahuja Introducing IndianFoodNet-30, a custom-made dataset with 5,500+ images of 30 popular Indian food items. |
|
|
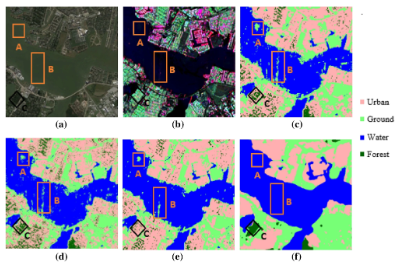 |
Rajat Garg, Anil Kumar, Nikunj Bansal, Manish Prateek, & Shashi Kumar Scientific Reports (nature) We aims at minimizing the misclassification of such highly vegetated and oriented urban targets into vegetation class with the help of deep learning. In this study, three machine learning algorithms Random Forest (RF), K-Nearest Neighbour (KNN), and Support Vector Machine (SVM) have been implemented along with a deep learning model DeepLabv3+ for semantic segmentation of Polarimetric SAR (PolSAR) data. |
|
|
Mayank Mishra, Tanupriya Choudhury, Tanmay Sarkar, Nikunj Bansal, Slim Smaoui, Maksim Rebezov, Mohammad Ali Shariati, & Jose Manuel Lorenzo Food Analytical Methods (springer) Introducing Allergen30, a custom-made dataset with 6,000+ images of 30 commonly used food items that can trigger an allergic reaction within the human body. This work is one of the first research attempts to train a deep learning based object detection model to detect the presence of such food items from images. |
|
|
Tanmay Sarkar, Tanupriya Choudhury, Nikunj Bansal, & Arunachalaeshwaran V R Food Analytical Methods (springer) Introducing, the Dataset for Adulterated Red Chilli Powder with Brick Powder. It contains high-quality images of Red Chilli Powder adulteration with Red Brick Powder at 12 different proportions:- 0%, 5%, 10%, 15%, 20%, 25%, 30%, 35%, 40%, 45%, 50%, and 100% adulterant. We are amongst the first research attempts to train machine learning-based algorithms to detect adulteration in Red Chilli Powder. |
|
|
 |
Hussain Falih Mahdi, Lav Kumar Gupta, Tanupriya Choudhury, & Nikunj Bansal International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT2022) IEEE Proposed Idea Mining Framework for Extracting Ideas From Online Reviews. |
|
|
Ritu Agarwal, Nikunj Bansal, Tanupriya Choudhury, Tanmay Sarkar, & Neelu Jyothi Ahuja International Conference on Advances and Applications of Artificial Intelligence and Machine Learning (ICAAAIML2022) Springer We are detecting Popular Indian Food Items using object detection Models on our custom dataset. |
 |
Nikunj Bansal, Goutam Datta, & Anupam Singh International Conference on Image Information Processing (ICIIP 21) IEEE We have applied NMT to low resources Indian languages, i.e. English-Hindi. We used a basic LSTM based Seq2Seq model and an attention-based Seq2Seq model with fixed vocabulary size. We merged the corpus collected from various sources and preprocessed them for further use. We used the BLEU metric score for evaluation. We also evaluated the Google Translator to compare our experimental results with it. |
|
|
 |
|
 |
|
|
|